
Data Contamination or Genuine Generalization? Disentangling LLM Performance on Benchmarks
DOI:
https://doi.org/10.70393/616a6e73.323836ARK:
https://n2t.net/ark:/40704/AJNS.v2n2a03Disciplines:
Computer ScienceSubjects:
Artificial IntelligenceReferences:
38Keywords:
LLM Memorization, Data Contamination, Generalization, Benchmark Evaluation, Perturbation Testing, Chain-of-Thought ReasoningAbstract
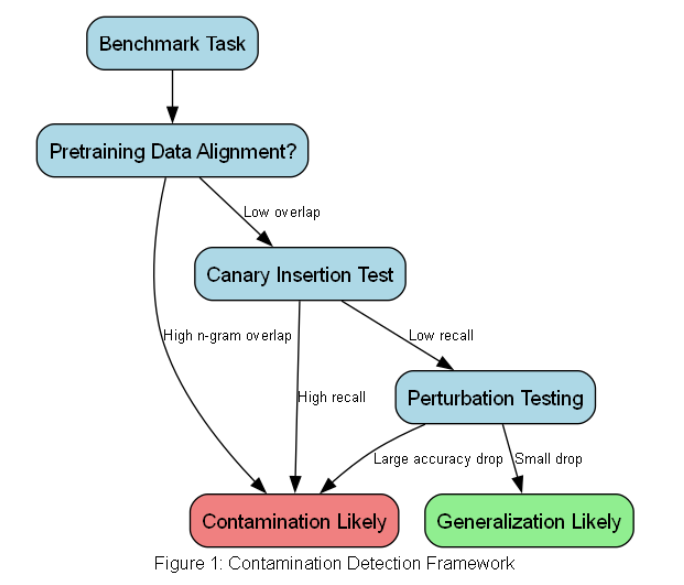
Large language models (LLMs) achieve high benchmark performance, but whether this stems from genuine generalization or data contamination remains unclear. This paper proposes a three-tier framework to disentangle these effects, combining n-gram alignment, canary insertion, and perturbation testing across open (Llama 2, Mistral) and closed (GPT-4) models. Our analysis reveals that: (1) Larger models exhibit higher contamination (18.1% n-gram overlap for Llama 2-70B) but smaller out-of-distribution (OOD) drops (−9.4%), suggesting scale mitigates memorization’s impact; (2) Perturbation experiments show factual recall is most vulnerable (e.g., −22.4% accuracy drop for entity swaps); (3) Chain-of-thought (CoT) evaluation uncovers hidden generalization (+21.3% gap for GPT-4), though humans outperform LLMs in robustness (e.g., −4.3% vs. −9.8% on swaps). We advocate for contamination-aware benchmarks and CoT-enhanced evaluation.
Downloads
References
[1] N. Carlini, F. Tramer, E. Wallace, M. Jagielski, A. Herbert-Voss, K. Lee, A. Roberts, T. Brown, D. Song, U. Erlingsson and others, "Extracting Training Data from Large Language Models," in USENIX Security Symposium, 2021.
[2] N. Kandpal, E. Wallace and C. Raffel, "Deduplicating Training Data Mitigates Privacy Risks in LLMs," in ICML, 2022.
[3] A. Elangovan, J. He and Y. Versley, "Measuring Memorization in Large Language Models," in EMNLP, 2023.
[4] J. Choi, K. Hickman, R. Balestriero and M. Poli, "Temporal Robustness of LLM Benchmarks," in ICLR, 2024.
[5] D. Ippolito, F. Tramèr, M. Nasr, C. Zhang, M. Jagielski, K. Lee, C. A. Choquette-Choo and N. Carlini, "Preventing Verbatim Memorization in Language Models Gives a False Sense of Privacy," in NeurIPS, 2022.
[6] J. Wei, Y. Tay, R. Bommasani, C. Raffel, B. Zoph, S. Borgeaud, D. Yogatama, M. Bosma, D. Zhou, D. Metzler and others, "Emergent Abilities of Large Language Models," in TMLR, 2022.
[7] C. Zhou, O. Levy, M. Ghazvininejad and L. Zettlemoyer, "LIMA: Less Is More for Alignment," in NeurIPS, 2023.
[8] E. J. Michaud, Z. Liu and M. Tegmark, "Benchmarking Benchmark Leakage in Large Language Models," in NeurIPS, 2023.
[9] R. Grosse, J. Bae and C. Anil, "Memorization in NLP Fine-tuning: A Causal Perspective," in ICLR, 2023.
[10] D. Hernandez, T. Brown, T. Conerly, N. DasSarma, T. Henighan, S. Johnston, C. Olsson, D. Amodei, N. Joseph and J. Kaplan, "Scaling Laws and Interpretability of Learning from Repeated Data," in ICLR, 2022.
[11] A. Srivastava, A. Rastogi, A. Rao, A. A. M. Shoeb, A. Abid, A. Fisch, A. Brown, A. Santoro, A. Gupta, A. Garriga-Alonso and others, "Data Contamination: From Memorization to Exploitation," in ACL, 2023.
[12] Z. Ke, S. Zhou, Y. Zhou, C. H. Chang and R. Zhang, "Detection of AI Deepfake and Fraud in Online Payments Using GAN-Based Models," arXiv preprint arXiv:2501.07033, 2025.
[13] D. Liu, "Contemporary model compression on large language models inference," arXiv preprint arXiv:2409.01990, 2024.
[14] D. Liu and K. Pister, "LLMEasyQuant–An Easy to Use Toolkit for LLM Quantization," arXiv preprint arXiv:2406.19657, 2024.
[15] D. Liu and Y. Yu, "Mt2st: Adaptive multi-task to single-task learning," arXiv preprint arXiv:2406.18038, 2024.
[16] D. Liu, R. Waleffe, M. Jiang and S. Venkataraman, "Graphsnapshot: Graph machine learning acceleration with fast storage and retrieval," arXiv preprint arXiv:2406.17918, 2024.
[17] M. Huo, K. Lu, Y. Li and Q. Zhu, "CT-PatchTST: Channel-Time Patch Time-Series Transformer for Long-Term Renewable Energy Forecasting," arXiv preprint arXiv:2501.08620, 2025.
[18] K. Li, J. Wang, X. Wu, X. Peng, R. Chang, X. Deng, Y. Kang, Y. Yang, F. Ni and B. Hong, "Optimizing automated picking systems in warehouse robots using machine learning," arXiv preprint arXiv:2408.16633, 2024.
[19] K. Li, L. Liu, J. Chen, D. Yu, X. Zhou, M. Li, C. Wang and Z. Li, "Research on reinforcement learning based warehouse robot navigation algorithm in complex warehouse layout," in 2024 6th International Conference on Artificial Intelligence and Computer Applications (ICAICA), 2024.
[20] K. Li, J. Chen, D. Yu, T. Dajun, X. Qiu, J. Lian, R. Ji, S. Zhang, Z. Wan, B. Sun and others, "Deep reinforcement learning-based obstacle avoidance for robot movement in warehouse environments," in 2024 IEEE 6th International Conference on Civil Aviation Safety and Information Technology (ICCASIT), 2024.
[21] D. Yu, L. Liu, S. Wu, K. Li, C. Wang, J. Xie, R. Chang, Y. Wang, Z. Wang and R. Ji, "Machine learning optimizes the efficiency of picking and packing in automated warehouse robot systems," in 2024 International Conference on Computer Engineering, Network and Digital Communication (CENDC 2024), 2024.
[22] Z. Li, J. H. Bookbinder and S. Elhedhli, "Optimal shipment decisions for an airfreight forwarder: Formulation and solution methods," Transportation Research Part C: Emerging Technologies, vol. 21, p. 17–30, 2012.
[23] Z. Zhou, J. Zhang, J. Zhang, Y. He, B. Wang, T. Shi and A. Khamis, "Human-centric Reward Optimization for Reinforcement Learning-based Automated Driving using Large Language Models," arXiv preprint arXiv:2405.04135, 2024.
[24] Y. He, X. Wang and T. Shi, "Ddpm-moco: Advancing industrial surface defect generation and detection with generative and contrastive learning," in International Joint Conference on Artificial Intelligence, 2024.
[25] C. Yang, Y. He, A. X. Tian, D. Chen, J. Wang, T. Shi, A. Heydarian and P. Liu, "Wcdt: World-centric diffusion transformer for traffic scene generation," arXiv preprint arXiv:2404.02082, 2024.
[26] X. Liang, M. Tao, Y. Xia, T. Shi, J. Wang and J. Yang, "Cmat: A multi-agent collaboration tuning framework for enhancing small language models," arXiv preprint arXiv:2404.01663, 2024.
[27] Y. He, S. Li, K. Li, J. Wang, B. Li, T. Shi, J. Yin, M. Zhang and X. Wang, "Enhancing Low-Cost Video Editing with Lightweight Adaptors and Temporal-Aware Inversion," arXiv preprint arXiv:2501.04606, 2025.
[28] M. Huo, K. Lu, Q. Zhu and Z. Chen, "Enhancing Customer Contact Efficiency with Graph Neural Networks in Credit Card Fraud Detection Workflow," arXiv preprint arXiv:2504.02275, 2025.
[29] Z. Chen, Z. Dai, H. Xing and J. Chen, "Multi-Model Approach for Stock Price Prediction and Trading Recommendations," Preprints, January 2025.
[30] Z. Chen, M. Hu, Y. Wang, J. Chen and M. Su, "Real-time New York Traffic Heatmap Analysis and Visualization," Preprints, January 2025.
[31] T. Jiang, L. Liu, J. Jiang, T. Zheng, Y. Jin and K. Xu, "Trajectory Tracking Using Frenet Coordinates with Deep Deterministic Policy Gradient," arXiv preprint arXiv:2411.13885, 2024.
[32] H. Liu, Y. Shen, C. Zhou, Y. Zou, Z. Gao and Q. Wang, "TD3 Based Collision Free Motion Planning for Robot Navigation," arXiv preprint arXiv:2405.15460, 2024.
[33] H. Zhao, Z. Ma, L. Liu, Y. Wang, Z. Zhang and H. Liu, "Optimized Path Planning for Logistics Robots Using Ant Colony Algorithm under Multiple Constraints," arXiv preprint arXiv:2504.05339, 2025.
[34] L. Xu, J. Liu, H. Zhao, T. Zheng, T. Jiang and L. Liu, "Autonomous Navigation of Unmanned Vehicle Through Deep Reinforcement Learning," arXiv preprint arXiv:2407.18962, 2024.
[35] Z. Li, S. Qiu and Z. Ke, "Revolutionizing Drug Discovery: Integrating Spatial Transcriptomics with Advanced Computer Vision Techniques," in 1st CVPR Workshop on Computer Vision For Drug Discovery (CVDD): Where are we and What is Beyond?, 2025.
[36] T. Zheng, Y. Jin, H. Zhao, Z. Ma, Y. Chen and K. Xu, "Deep Reinforcement Learning Based Coverage Path Planning in Unknown Environments," Preprints preprints:202503.0300.v1, March 2025.
[37] V. Feldman, "Does Learning Require Memorization?," STOC, 2020.
[38] D. Yu, S. Naik and others, "Differentially Private Fine-Tuning of Language Models," ICLR, 2021.
Downloads
Published
How to Cite
Issue
Section
ARK
License
Copyright (c) 2025 The author retains copyright and grants the journal the right of first publication.

This work is licensed under a Creative Commons Attribution 4.0 International License.









