
Research on Optimizing Lightweight Small Models Based on Generating Training Data with ChatGPT
DOI:
https://doi.org/10.5281/zenodo.10841043References:
24Keywords:
Deep Learning Optimization, Lightweight Model Enhancement, Computation EfficiencyAbstract
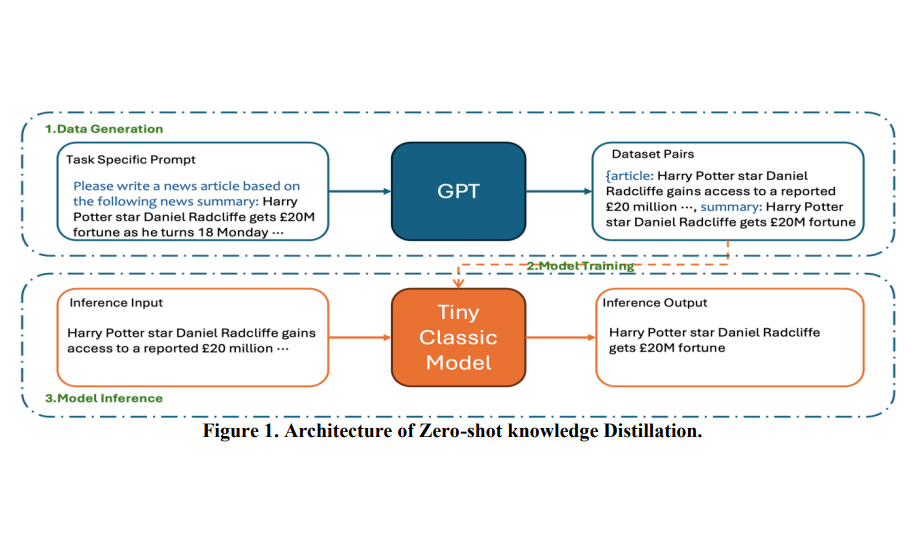
This study aims to explore a method for optimizing lightweight small models in the field of deep learning by leveraging large models to generate training data. By introducing large-scale pre-trained models and enriching the training set through data generation, we enhance the performance of small models. The experimental results indicate that this strategy not only effectively improves the accuracy of lightweight models but also reduces computational expenses in resource-constrained environments.
Downloads
References
Logan, R. L., IV, Balažević, I., & Wallace, E. et al. (2021). Cutting down on prompts and parameters: Simple few-shot learning with language models.
Brown, T. B., Mann, B., & Ryder, N. et al. (2020). Language models are few-shot learners. arXiv preprint arXiv:2005.14165.
Dai, W., Tao, J., & Yan, X. et al. (2023). Addressing unintended bias in toxicity detection: An LSTM and attention-based approach. In 2023 5th International Conference on Artificial Intelligence and Computer Applications (ICAICA), 375–379.
Devlin, J., Chang, M.-W., & Lee, K. et al. (2018). Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805.
Friedman, J. H. (2001). Greedy function approximation: A gradient boosting machine. Annals of Statistics, 1189–1232.
Hermann, K. M., Kociský, T., & Grefenstette, E. et al. (2015). Teaching machines to read and comprehend. In NIPS, 1693–1701.
Hochreiter, S., & Schmidhuber, J. (1997). Long short-term memory. Neural Computation, 9(8), 1735–1780.
Lewis, M., Liu, Y., & Goyal, N. et al. (2019). Bart: Denoising sequence-to-sequence pre-training for natural language processing. arXiv preprint arXiv:1910.13461.
Li, S., Kou, P., & Ma, M. et al. (2024). Application of semi-supervised learning in image classification: Research on fusion of labeled and unlabeled data. IEEE Access, 12, 27331–27343.
Liu, Y., Yang, H., & Wu, C. (2023). Unveiling patterns: A study on semi-supervised classification of strip surface defects. IEEE Access, 11, 119933–119946.
Liu, T., Xu, C., & Qiao, Y. et al. (2024). News recommendation with attention mechanism. Journal of Industrial Engineering and Applied Science, 2(1), 21–26.
Su, J., Jiang, C., & Jin, X. et al. (2024). Large language models for forecasting and anomaly detection: A systematic literature review. arXiv preprint arXiv:2402.10350.
Mishra, S., Khashabi, D., & Baral, C. et al. (2022). Cross-task generalization via natural language crowdsourcing instructions.
Miyato, T., Maeda, S., & Koyama, M. et al. (2018). Virtual adversarial training: A regularization method for supervised and semi-supervised learning.
Perez, E., Kiela, D., & Cho, K. (2021). True few-shot learning with language models. In Advances in Neural Information Processing Systems, 34, 11054–11070.
Puri, R., & Catanzaro, B. (2019). Zero-shot text classification with generative language models.
Raffel, C., Shazeer, N., & Roberts, A. et al. (2019). Exploring the limits of transfer learning with a unified text-to-text transformer. arXiv preprint arXiv:1910.10683.
Sanh, V., Webson, A., & Raffel, C. et al. (2022). Multitask prompted training enables zero-shot task generalization.
Schick, T., & Schütze, H. (2021). Few-shot text generation with pattern-exploiting training.
See, A., Liu, P. J., & Manning, C. D. (2017). Get to the point: Summarization with pointer-generator networks. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 1073–1083.
Tam, D., Menon, R. R., & Bansal, M. et al. (2021). Improving and simplifying pattern exploiting training. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, 4980–4991.
Xu, H., Chen, Y., & Du, Y. et al. (2022). ZeroPrompt: Scaling prompt-based pretraining to 1,000 tasks improves zero-shot generalization.
Ye, Q., Lin, B. Y., & Ren, X. (2021). CrossFit: A few-shot learning challenge for cross-task generalization in NLP.
Yin, W., Hay, J., & Roth, D. (2019). Benchmarking zero-shot text classification: Datasets, evaluation and entailment approach. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), 3914–3923.
Downloads
Published
How to Cite
Issue
Section
License
Copyright (c) 2024 Journal of Industrial Engineering and Applied Science

This work is licensed under a Creative Commons Attribution 4.0 International License.







